
티스토리 뷰
딥러닝 프로세스
딥러닝 모델 구축 및 훈련을 위해서는 다음과 같은 프로세스를 따른다.
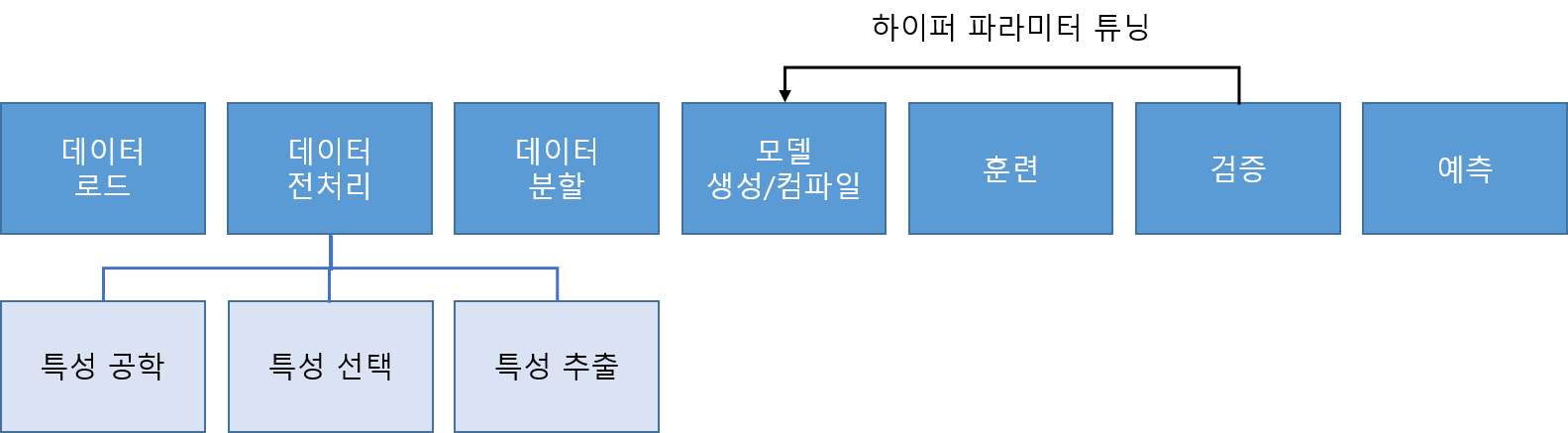
데이터 전처리, 모델의 생성, 컴파일, 훈련은 모델의 훈련을 위한 필수 프로세스로 누락되는 단계는 없다. 예측(predict)은 예측용 데이터 셋을 입력하여 모델 예측 값을 얻는 과정이다. 검증(evaluate)은 모델의 성능을 평가하는 단계를 말한다.
데이터 전처리
데이터를 모델에 주입하기 전에 데이터를 가공하는 단계를 말한다. 데이터 셋의 종류와 적용하려는 문제 유형에 따라 전처리 방법은 다양하다.
때에 따라서는 배열의 차원을 변경하거나 스케일을 조정할 수 있다. 전처리 단계에서 데이터 셋의 형태나 차원을 미리 구상해야 다음 단계에서 모델을 설계할 때 입력할 데이터 셋의 형태를 올바르게 정의할 수 있다. 전처리 단계에서 처리한 데이터 셋의 형태와 다음 단계에서 생성할 모델이 입력받을 데이터셋의 형태가 다르다면 에러가 발생할 수 있다.
모델 생성
모델의 구조를 정의하고 생성하는 단계다. 모델을 생성하는 방법은 크게 세 가지로 구분할 수 있으며, 순차적인 구조의 모델은 Sequential API로 구현한다. 다중 입력 및 출력을 가지고 복잡한 구조를 갖는 모델은 Functional API 혹은 Model Sub classing 방법으로 구현할 수 있다. 다음파트에서 자세한 방법에 대해 학습할 예정이므로, 여기서는 설명을 생략한다.
모델 컴파일
딥러닝 모델의 구조를 정의하고 생성한 뒤에는 생성된 모델 훈련에 사용한 손실함수(loss), 옵티마이저(optimizer). 평가지표(metrics) 등을 정의한다. 모델 인스턴스에 compile() 메소드를 적용하고, 앞에서 열거한 여러 가지 속성 값을 설정한다. 이 과정을 컴파일 단계라고 한다.
모델 훈련
모델을 훈련하는 단계이다. fit() 함수에 모델 훈련에 필요한 정보를 매개변수(또는 파라미터로 전달한다. 훈련 데이터 셋, 검증 데이터 셋, epoch, 배치(batch) 크기 및 콜백(Callback) 함수 등을 지정한다. 자세한 설명은 뒤에서 예제와 함께 다룰 예정이다.
모델 검증
훈련이 완료된 모델을 검증하는 단계이다. 모델을 훈련할 때 사용하지 않은 검증 데이터 셋을 모델에 입력하고 모델의 예측 값을 정답과 비교하여 평가지표를 계산한다. 반환된 검증 결과를 토대로 잠재적인 모델의 성능 평가가 이뤄진다. 검증 결과를 바탕으로 다시 모델 생성 단계로 돌아가 모델 수정을 하고, 컴파일 및 훈련 과정을 거쳐 재평가하는 단계를 통해 목표 성능에 도달할 때까지 이 과정을 계속 반복한다.
모델 예측.
훈련과 검증이 완료된 모델로 테스트 셋에 대하여 모델이 예측하고 그 결과를 반환한다.
'Remote Sensing' 카테고리의 다른 글
| sentinel-2 위성영상의 파장영역과 식생지수 값에 따른 식생상태 (0) | 2022.07.27 |
|---|---|
| [실습-01] Landsat 8 이미지 다운로드 (0) | 2022.07.20 |
| 원격탐사와 영상판독 원리 (0) | 2022.07.09 |
| 원격탐사와 SPOT위성 및 센티넬(Sentinel) 위성 (0) | 2022.07.01 |
| 원격탐사와 Landsat 위성 8호 (0) | 2022.06.30 |