
티스토리 뷰
지난 글에서는 CNN(Convolutional Neural Networks)(이미지 기반 모델)을 사용하여 도시 홍수 취약성을 매핑하기 위한 데이터 세트를 준비했습니다. 이 문서에서는 이미지를 읽고 CNN 모델을 훈련하고 이를 사용하여 도시의 홍수 취약성을 매핑하는 방법을 보여줍니다.
이 일련의 글들은 Geomatics, Natural Hazards and Risk에 게시된 " Towards urban flood susceptibility mapping using data-driven models in Berlin, Germany " 논문을 파이썬 코드로 요약하고 설명합니다 .
지난 기사에서 두 개의 폴더(Flooded 및 NotFlooded)를 준비했습니다. 각 폴더에는 플러드 인벤토리의 각 위치에서 예측 기능을 나타내는 이미지가 포함되어 있습니다. 이제 이러한 이미지를 읽고 모델에 대한 입력으로 사용할 준비를 해야 합니다.
<코드 1>
import numpy as np
import matplotlib.pyplot as plt
import rasterio
import os
import cv2
import pandas as pd
# Read the preditive features and the label (Notflooded=0 , flooded=1)
data_path=r"D:\Predictive_features" # created in data_preperation script (last article)
CATEGORIES= ["NotFlooded", "Flooded"]
IMG_SIZE=23샘플을 플로팅하여 데이터에 오류가 없는지 확인합시다.
<코드 2>
# Check the images
# plot the first band in the first image
for category in CATEGORIES:
path=os.path.join(data_path,category) # Path to flooded and NotFlooded dir
for img in os.listdir(path):
img_open=rasterio.open(os.path.join(path,img))
img_array=img_open.read(1) # open the image and read the first band
#img_array= np.where(img_array < 0, np.nan,img_array)
#mean=np.nanmean(img_array)
#img_array= np.where(np.isnan(img_array), mean,img_array)
plt.imshow(img_array,cmap="gray")
plt.show()
#print(img_array)
break
break
우리는 11개의 예측 기능을 사용했으며 각 기능은 이미지에서 밴드로 표시됩니다. 즉, 각 이미지에는 11개의 밴드가 있습니다. 이미지를 읽어야 합니다(11개 밴드 및 NumPy 배열로 저장). 배열 목록에 각 예측 기능을 저장하는 것을 선호합니다. 따라서 각 예측 기능에 대해 빈 목록을 만든 다음 합성 래스터 이미지에서 동일한 밴드 순서로 목록에 넣었습니다.
<코드 3>
# create a list for each predective feature
DEM=[]
Slope=[]
TWI=[]
DTRoad=[]
DTRiver=[]
CN=[]
Rain=[]
Aspect=[]
Curve=[]
Freq=[]
DTDrainage=[]
y=[]
# we have 11 predictive features
# every feature is presented in one band
# create a list which include the 11 predictive feature to
# loop over the predictive features
predictive_features=[DEM, Slope, TWI, DTRoad, DTRiver, CN, Rain, Aspect, Curve, Freq, DTDrainage] # the features muss be in the same order as the bands in the composite raster
이제 아래 기능을 사용하여 이미지를 읽고 목록에 저장할 수 있습니다. 레이블도 저장해야 합니다(위치가 침수되지 않은 경우 0, 위치가 침수된 경우 1). 침수 위치와 침수되지 않은 위치는 별도의 폴더에 저장됩니다. Notflooded 폴더에서 이미지를 읽으면 flooded 폴더의 이미지에 대해 레이블 0과 1을 얻습니다.
<코드 4>
def create_training_data():
for i in range(len(predictive_features)):
print(i+1)
for category in CATEGORIES:
path= os.path.join(data_path,category) # Path to flooded and NotFlooded dir
class_num= CATEGORIES.index(category)
for img in os.listdir(path):
try:
img_open=rasterio.open(os.path.join(path,img))
print(category,img,class_num)
img_array=img_open.read(i+1)
#img_array= np.where(img_array < 0, np.nan,img_array)
#mean=np.nanmean(img_array)
#img_array= np.where(np.isnan(img_array), mean,img_array)
#new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # resize to normalize data size
predictive_features[i].append(img_array)
if i==0:
y.append(class_num)
#print(class_num)
except Exception as e:
pass
create_training_data()
이제 Numpy 배열 목록에 모든 이미지가 저장되었습니다. 이러한 배열 목록을 다음 차원(이미지 수 * 이미지 크기 * 이미지 크기 * 밴드 수)의 배열로 변환해야 합니다. 샘플 데이터(84 * 23 * 23 * 1)를 사용합니다. 그런 다음 하나의 배열에 있는 모든 예측 기능을 차원( 84 * 23 * 23 *11 )과 결합해야 합니다.
<코드 5>
# convert the predictive feature lists to numpy arrays
DEM_array=np.array(DEM).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
Slope_array=np.array(Slope).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
TWI_array=np.array(TWI).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
DTRoad_array=np.array(DTRoad).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
DTRiver_array=np.array(DTRiver).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
CN_array=np.array(CN).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
DTDrainage_array=np.array(DTDrainage).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
Aspect_array=np.array(Aspect).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
Curvature_array=np.array(Curve).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
Freq_Curve_array=np.array(Freq).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
Rain_array=np.array(Rain).reshape(-1, IMG_SIZE, IMG_SIZE, 1)
# concatenate all the predicvtive feature arrays into one array
X_array=np.concatenate([DEM_array,Slope_array,TWI_array,DTRoad_array, DTRiver_array,CN_array,Rain_array,Aspect_array, Curvature_array, Freq_Curve_array, DTDrainage_array], axis=-1)
그런 다음 데이터를 교육(60%), 검증(20%) 및 테스트(20%)로 나눕니다. 먼저 훈련과 테스트로 나눈 다음 나중에 Keras를 사용하여 훈련 데이터를 훈련과 검증으로 나눕니다.
<코드 6>
# split the data into training (60%), validation (20%) and testing (20%)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X_array,y,test_size=0.2,random_state=42)1. CNN 모델: LeNet5 — 아키텍처
논문에서는 그림 1과 같은 LeNet5 아키텍처를 사용했습니다.
이 아키텍처는 간단하고 모델을 교육할 데이터가 많지 않을 때 적합합니다.
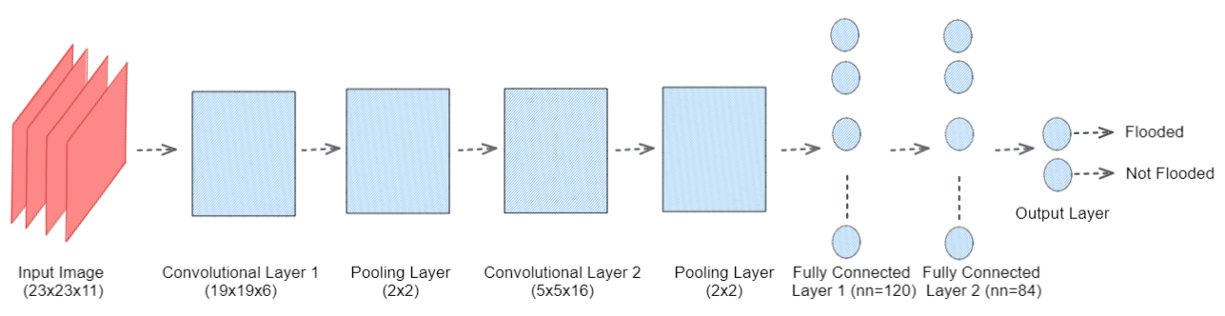
<코드 7>
import keras
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Dropout
from keras.callbacks import TensorBoard
NAME = "LeNet"
model = Sequential()
#Layer 1
#Conv Layer 1
model.add(Conv2D(filters = 6,
kernel_size = 5,
strides = 1,
activation = 'relu',
input_shape = (23,23,11)))
#Pooling layer 1
model.add(MaxPooling2D(pool_size = 2, strides = 2))
#add a droupout
model.add(Dropout(0.4))
#Layer 2
#Conv Layer 2
model.add(Conv2D(filters = 16,
kernel_size = 5,
strides = 1,
activation = 'relu',
input_shape = (14,14,6)))
#Pooling Layer 2
model.add(MaxPooling2D(pool_size = 2, strides = 2))
#add a droupout
model.add(Dropout(0.4))
#Flatten
model.add(Flatten())
#Layer 3
#Fully connected layer 1
model.add(Dense(units = 120, activation = 'relu'))
#add a droupout
model.add(Dropout(0.4))
#Layer 4
#Fully connected layer 2
model.add(Dense(units = 84, activation = 'relu'))
model.add(Dropout(0.4))
#Layer 5
#Output Layer
model.add(Dense(units = 1, activation = 'sigmoid'))
from keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint = ModelCheckpoint("LeNet.h5", monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
early = EarlyStopping(monitor='val_loss', min_delta=0, patience=20, verbose=1, mode='auto')
tensorboard = TensorBoard(log_dir="logs/{}".format(NAME))
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
model.summary()
history=model.fit(x_train ,y_train, batch_size=1024, epochs = 1000, validation_split=0.25, callbacks=[checkpoint,early,tensorboard])
2. 모델 평가
모델을 교육한 후에는 먼저 모델이 오버피팅인지 언더피팅인지 확인해야 합니다. 각 에포크에서 훈련 및 검증 정확도와 손실을 볼 수 있습니다. 모델은 두 데이터 세트에서 유사한 성능을 가져야 합니다.
<코드 8>
#plot the training and validation accuracy and loss at each epoch
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'y', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs, acc, 'y', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
그런 다음 성능 지표를 정확도, 카파 및 ROC 곡선 아래 면적으로 계산할 수 있습니다.
<코드 9>
_, acc = model.evaluate(x_test, y_test)
print("Accuracy = ", (acc * 100.0), "%")
#Confusion matrix
#We compare labels and plot them based on correct or wrong predictions.
#Since sigmoid outputs probabilities we need to apply threshold to convert to label.
mythreshold=0.5
from sklearn.metrics import confusion_matrix
y_pred = (model.predict(x_test)>= mythreshold).astype(int)
cm=confusion_matrix(y_test, y_pred)
print(cm)
from sklearn.metrics import classification_report
target_names = ['NotFlooded', 'Flooded']
print(classification_report(y_test, y_pred_test, target_names=target_names))
from sklearn.metrics import cohen_kappa_score
cohen_kappa_score(y_test, y_pred, labels=None, weights=None)
#Check the confusion matrix for various thresholds. Which one is good?
#Need to balance positive, negative, false positive and false negative.
#ROC can help identify the right threshold.
#Receiver Operating Characteristic (ROC) Curve is a plot that helps us
#visualize the performance of a binary classifier when the threshold is varied.
#ROC
from sklearn.metrics import roc_curve
y_preds = model.predict(x_test).ravel()
fpr, tpr, thresholds = roc_curve(y_test, y_preds)
plt.figure(1)
plt.plot([0, 1], [0, 1], 'y--')
plt.plot(fpr, tpr, marker='.')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.show()
#AUC
#Area under the curve (AUC) for ROC plot can be used to understand how well a classifier is performing.
#% chance that the model can distinguish between positive and negative classes.
from sklearn.metrics import auc
auc_value = auc(fpr, tpr)
print("Area under curve, AUC = ", auc_value)
마지막으로 동일한 단계를 사용하여 전체 연구 지역에 대한 데이터를 준비하고 전체 지역에 대한 홍수 취약성을 예측할 수 있습니다.
연구 영역을 매핑하는 데 너무 많은 시간이 걸리므로 미세한 공간 해상도(< 10m)로 CNN을 사용하는 것은 실용적이지 않습니다.
CNN 모델이 그림 2와 같이 미세 해상도(5 및 2m)에서 침수 취약성이 높은 지역으로만 지형학적 함몰부를 인식할 수 있음을 발견했습니다.
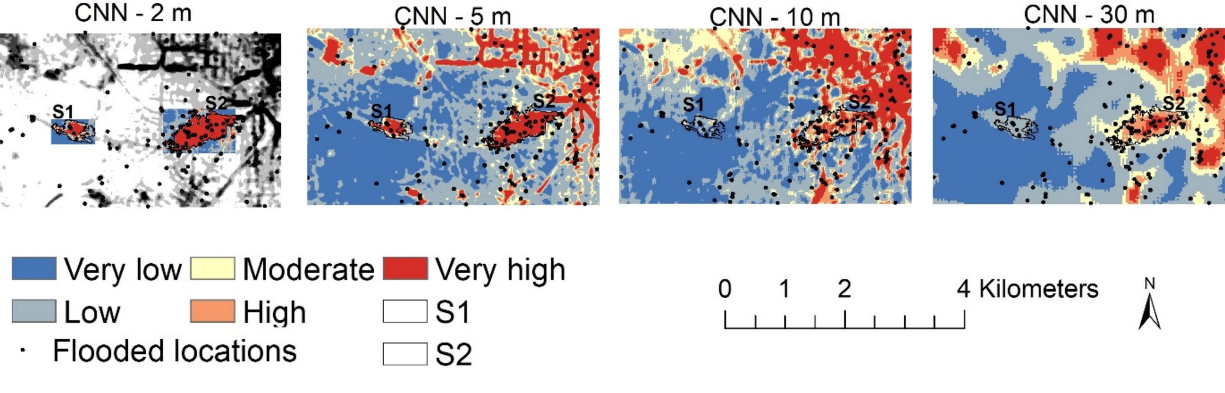
'Remote Sensing' 카테고리의 다른 글
| 센티넬 영상 데이터 다운로드 (0) | 2024.06.09 |
|---|---|
| Landsat 8 밴드 및 밴드 조합 (0) | 2024.01.06 |
| AI 모델을 사용한 도시 홍수 취약성 지도 제작(4) (0) | 2023.02.20 |
| AI 모델을 사용한 도시 홍수 취약성 지도 제작(3) (0) | 2023.02.18 |
| 위성사진과 python을 이용하여 토지이용 변화를 정량화 하기 (0) | 2023.02.17 |