
티스토리 뷰
이번글은 딥러닝 Unet 모델을 이용하고 센티넬 위성영상을 이용해서 토지피복을 분류하는 과정을 설명한다.
1. 데이터 준비
- 구글어스엔진을 이용해서 대상지역의 센티넬 위성영상과 기존에 제작된 토지피복지도를 다운받는다.
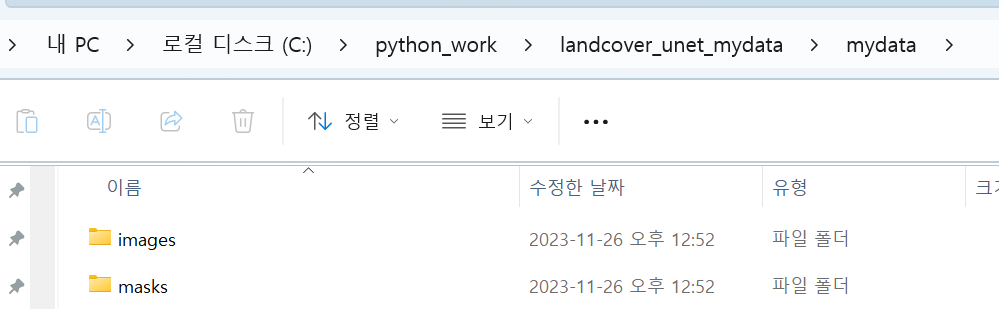
2. 데이터 폴더 준비하기
- 센티넬 위성영상은 images 폴더에 두고 기존 토지피복지도는 masks폴더에 둔다



3. 가상환경을 실행하고 쥬피터 노트북을 실행한다.

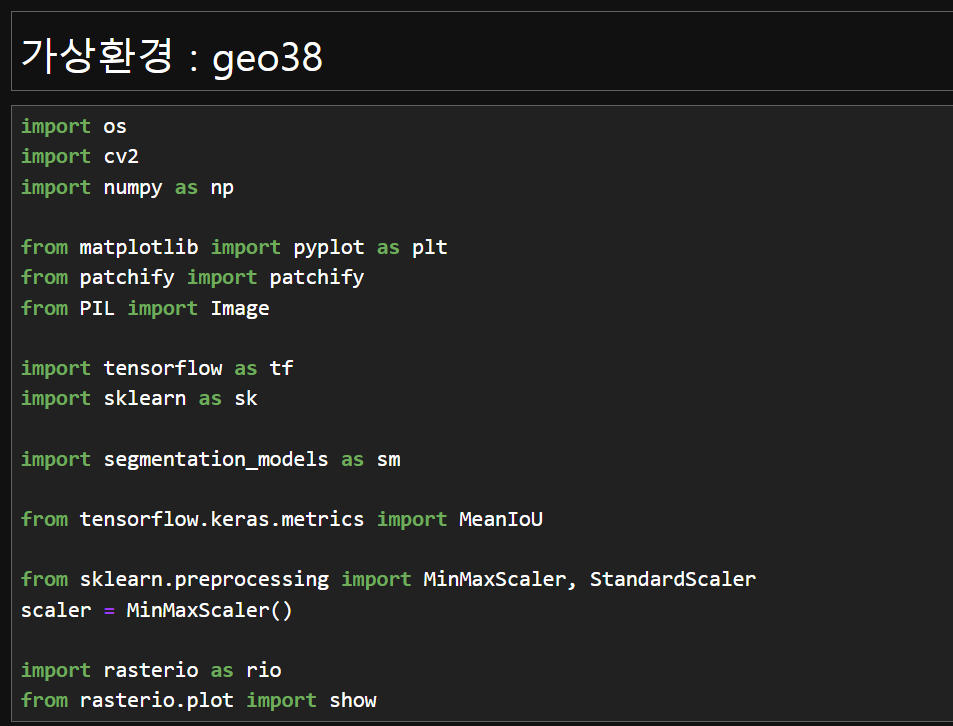
4. 딥러닝 유넷을 이용하여 토지피복분류를 하기 위해서 필요한 패키지를 불러온다.
- 가상환경은 geo38 환경에서 진행한다.
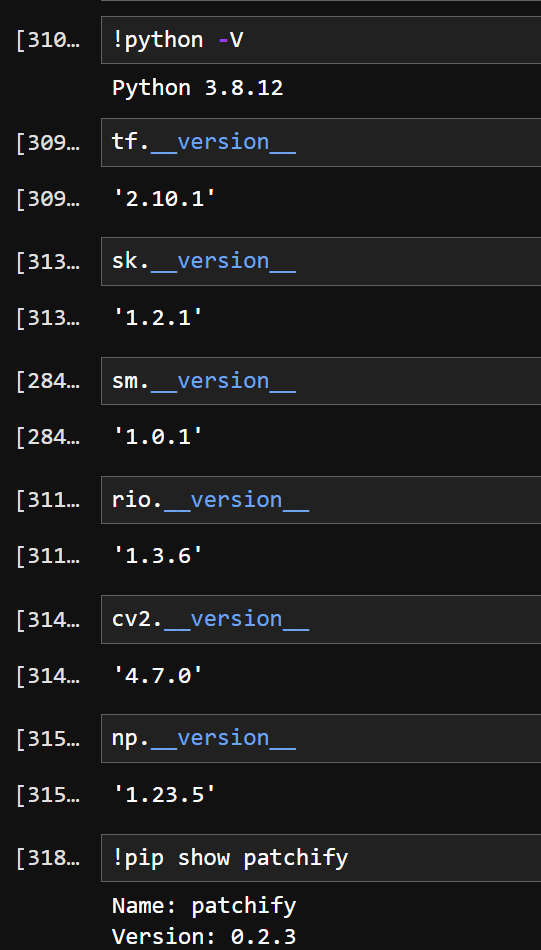
5. 패키지의 버전을 확인한다.
6. 딥러닝 유넷 모델을 학습시킬 데이터를 생성한다.
1) 데이터 경로를 지정한다.
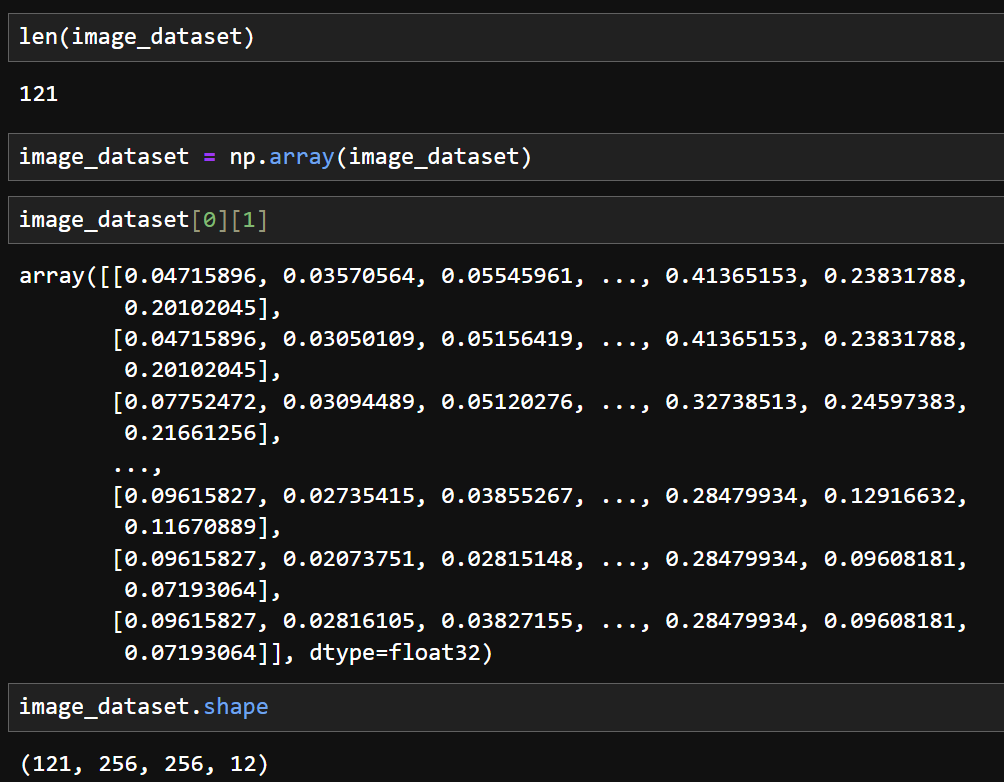
2) 센티넬 위성영상자료를 읽어와 np array 형태의 자료로 만든다. 이때 원본 위성영상자료를 256 x 256 크기로 만든다.
image_dataset = []
for path, subdirs, files in os.walk(root_directory):
#print(path)
dirname = path.split('/')[-1]
if dirname == 'images': #Find all 'images' directories
images = os.listdir(path) #List of all image names in this subdirectory
print(images)
for i, image_name in enumerate(images):
if image_name.endswith(".tif"): #Only read jpg images...
image_o = rio.open(path+"/"+image_name)
image = image_o.read()
print(image_o.meta)
print(image.shape)
image = np.moveaxis(image, 0, -1)
print(image.shape)
# print(image)
SIZE_X = (image.shape[1]//patch_size)*patch_size #Nearest size divisible by our patch size
SIZE_Y = (image.shape[0]//patch_size)*patch_size #Nearest size divisible by our patch size
print(image.shape[1], image.shape[0])
# image = Image.fromarray(image)
# image = image.crop((0 ,0, SIZE_X, SIZE_Y)) #Crop from top left corner
#image = image.resize((SIZE_X, SIZE_Y)) #Try not to resize for semantic segmentation
image =image[: SIZE_X, : SIZE_Y]
image = np.array(image)
print(image.shape)
#Extract patches from each image
print("Now patchifying image:", path+"/"+image_name)
patches_img = patchify(image, (patch_size, patch_size, 12), step=patch_size) #Step=256 for 256 patches means no overlap
for i in range(patches_img.shape[0]):
for j in range(patches_img.shape[1]):
single_patch_img = patches_img[i,j,:,:]
#Use minmaxscaler instead of just dividing by 255.
single_patch_img = scaler.fit_transform(single_patch_img.reshape(-1, single_patch_img.shape[-1])).reshape(single_patch_img.shape)
#single_patch_img = (single_patch_img.astype('float32')) / 255.
single_patch_img = single_patch_img[0] #Drop the extra unecessary dimension that patchify adds.
image_dataset.append(single_patch_img)
3) 불러온 센티넬 위성영상자료의 구조를 확인한다. 256 x 256 크기로 생성된 12개의 밴드를 가진 121개 np array 데이터이다.
4) 센티넬 영상을 확인한다. 여기서 센티넬 12개 밴드에서 7번째, 3번째, 2번째 데이터를 이용하여 출력하는데 이는 근적외선밴드, 적색광 밴드, 녹색광 밴드로 구성된 false color composit 영상을 확인할 수 있다.
# Read the grid values into numpy arrays
nir_img = image_dataset[0][:, :, 7]
red_img = image_dataset[0][:, :, 3]
green_img = image_dataset[0][:, :, 2]
# Normalize the values using the function that we defined earlier
# nirn = normalize(nir)
# redn = normalize(red)
# greenn = normalize(green)
# Create the composite by stacking
nrg_img = np.dstack((nir_img, red_img, green_img))
# Let's see how our color composite looks like
plt.imshow(nrg_img)
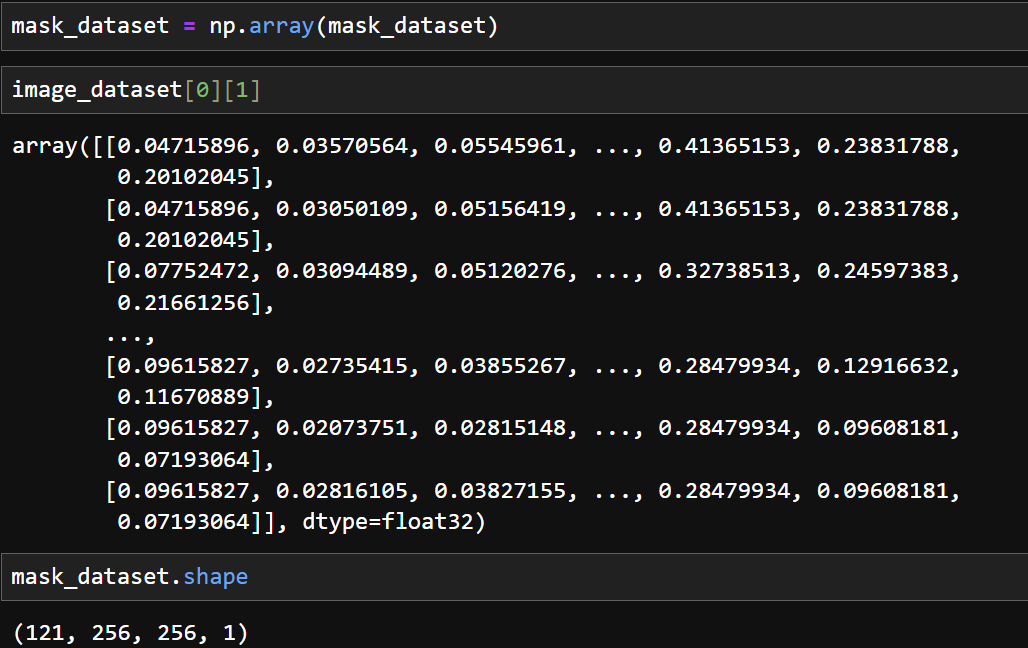
5) 토지피복 유형의 정답이 되는 기존 제작된 토지피복지도를 불러와 np array 형태의 자료로 만든다.
mask_dataset = []
for path, subdirs, files in os.walk(root_directory):
#print(path)
dirname = path.split('/')[-1]
if dirname == 'masks': #Find all 'images' directories
masks = os.listdir(path) #List of all image names in this subdirectory
for i, mask_name in enumerate(masks):
if mask_name.endswith(".tif"): #Only read png images... (masks in this dataset)
mask_o = rio.open(path+"/"+ mask_name) #Read each image as Grey (or color but remember to map each color to an integer)
mask = mask_o.read()
print(mask_o.meta)
print(mask.shape)
mask = np.moveaxis(mask, 0, -1)
print(mask.shape)
SIZE_X = (mask.shape[1]//patch_size)*patch_size #Nearest size divisible by our patch size
SIZE_Y = (mask.shape[0]//patch_size)*patch_size #Nearest size divisible by our patch size
print(mask.shape[1], mask.shape[0])
# mask = Image.fromarray(mask)
# mask = mask.crop((0 ,0, SIZE_X, SIZE_Y)) #Crop from top left corner
#mask = mask.resize((SIZE_X, SIZE_Y)) #Try not to resize for semantic segmentation
mask =mask[: SIZE_X, : SIZE_Y]
mask = np.array(mask)
print(mask.shape)
#Extract patches from each image
print("Now patchifying mask:", path+"/"+ mask_name)
patches_mask = patchify(mask, (patch_size, patch_size, 1), step=patch_size) #Step=256 for 256 patches means no overlap
for i in range(patches_mask.shape[0]):
for j in range(patches_mask.shape[1]):
single_patch_mask = patches_mask[i,j,:,:]
#single_patch_img = (single_patch_img.astype('float32')) / 255. #No need to scale masks, but you can do it if you want
single_patch_mask = single_patch_mask[0] #Drop the extra unecessary dimension that patchify adds.
mask_dataset.append(single_patch_mask)
6) 기존 토지피복지도의 구조를 확인한다. 256 x 256 크기로 생성된 1개의 밴드를 가진 121개 데이터이다.
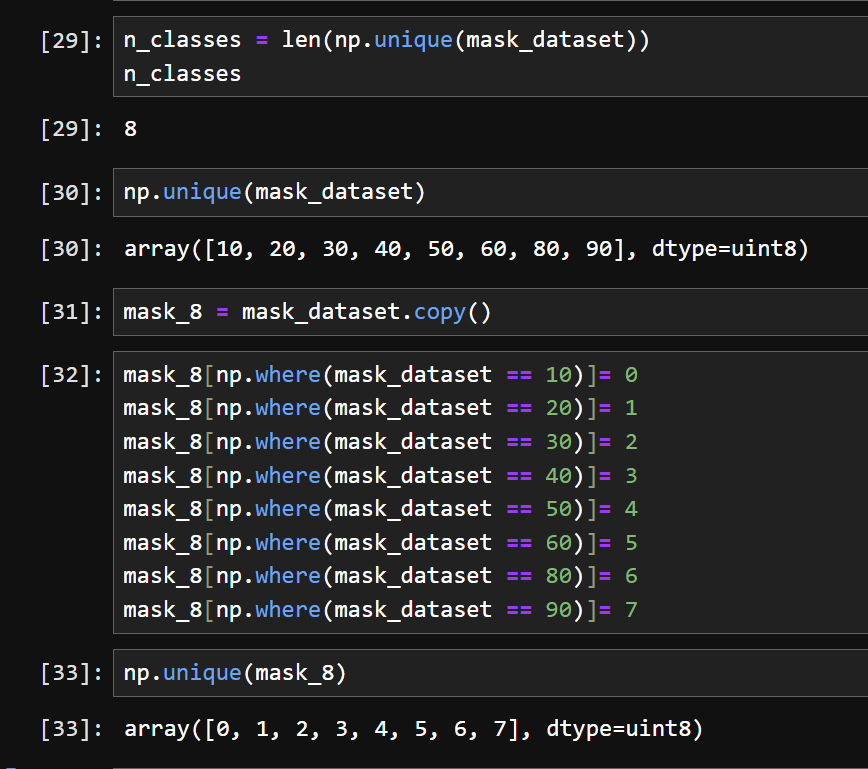
7) 정답이 되는 label 데이터 만드기 위해서 기존 토지피복유형을 확인하고 클래스 값을 재부여한다.
8) 레벨 값을 원핫인코딩 형태로 변경한다.
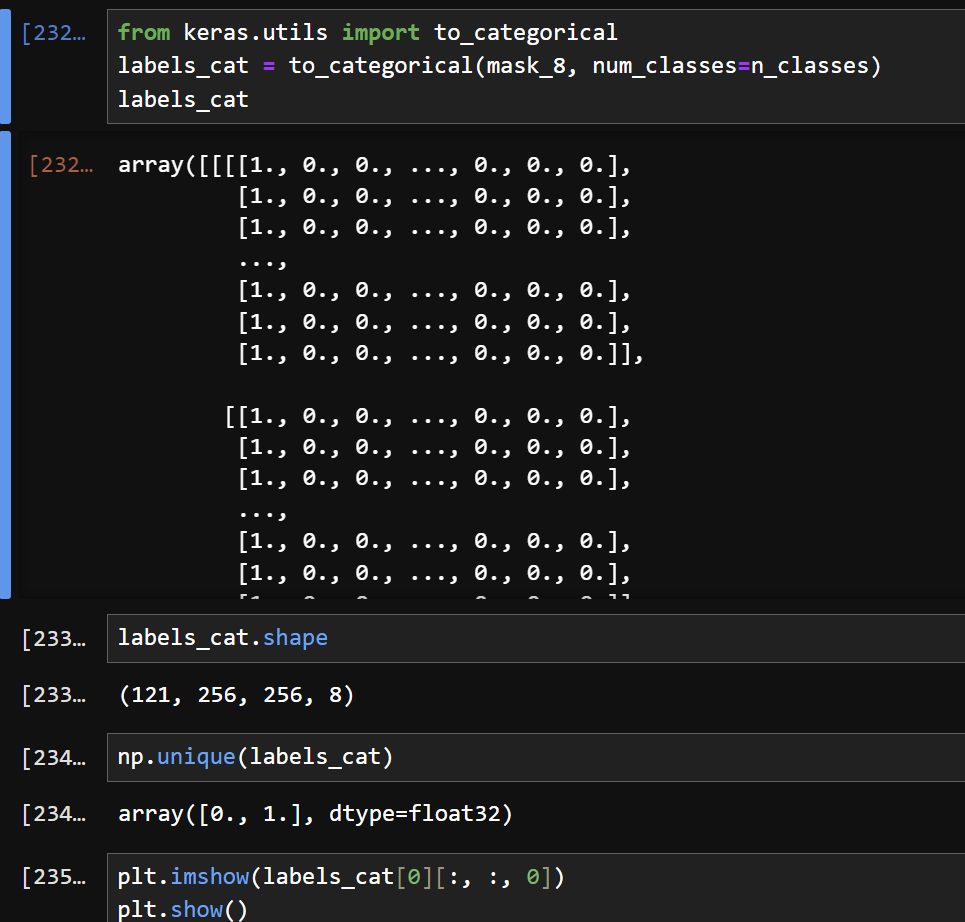
9) 학습데이터와 검증데이터를 구분한다.

10) 딥러닝 unet 모델 정의
- 관련 패키지를 불러오고 정확도 척도인 jacard_coef를 정의한 다음, unet 모델을 정의한다.
- 이때 unet 모델에서 n_classes는 8이고 IMG_CHANNELS는 12이다.
- 추후 토지피복 유형의 수가 달라지고 센티넬 위성영상에 식생지수 등 밴드를 추가할 때 고려해야한다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate, Conv2DTranspose, BatchNormalization, Dropout, Lambda
from tensorflow.keras import backend as K
def jacard_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (intersection + 1.0) / (K.sum(y_true_f) + K.sum(y_pred_f) - intersection + 1.0)
################################################################
def multi_unet_model(n_classes=8, IMG_HEIGHT=256, IMG_WIDTH=256, IMG_CHANNELS=12):
#Build the model
inputs = Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
#s = Lambda(lambda x: x / 255)(inputs) #No need for this if we normalize our inputs beforehand
s = inputs
#Contraction path
c1 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = Dropout(0.2)(c1) # Original 0.1
c1 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = MaxPooling2D((2, 2))(c1)
c2 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = Dropout(0.2)(c2) # Original 0.1
c2 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = MaxPooling2D((2, 2))(c2)
c3 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = Dropout(0.2)(c3)
c3 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = MaxPooling2D((2, 2))(c3)
c4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = Dropout(0.2)(c4)
c4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = MaxPooling2D(pool_size=(2, 2))(c4)
c5 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = Dropout(0.3)(c5)
c5 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)
#Expansive path
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = concatenate([u6, c4])
c6 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = Dropout(0.2)(c6)
c6 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6)
u7 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = concatenate([u7, c3])
c7 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = Dropout(0.2)(c7)
c7 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7)
u8 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = concatenate([u8, c2])
c8 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = Dropout(0.2)(c8) # Original 0.1
c8 = Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8)
u9 = Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = concatenate([u9, c1], axis=3)
c9 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = Dropout(0.2)(c9) # Original 0.1
c9 = Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)
outputs = Conv2D(n_classes, (1, 1), activation='softmax')(c9)
model = Model(inputs=[inputs], outputs=[outputs])
#NOTE: Compile the model in the main program to make it easy to test with various loss functions
#model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
#model.summary()
return model
11) 정의된 unet 모델을 컴파일 한다.
- 초기 가중치(weights)는 토지피복유형 개수에 맞게 8개를 동일하게 0.125(1/8)를 부여한다.
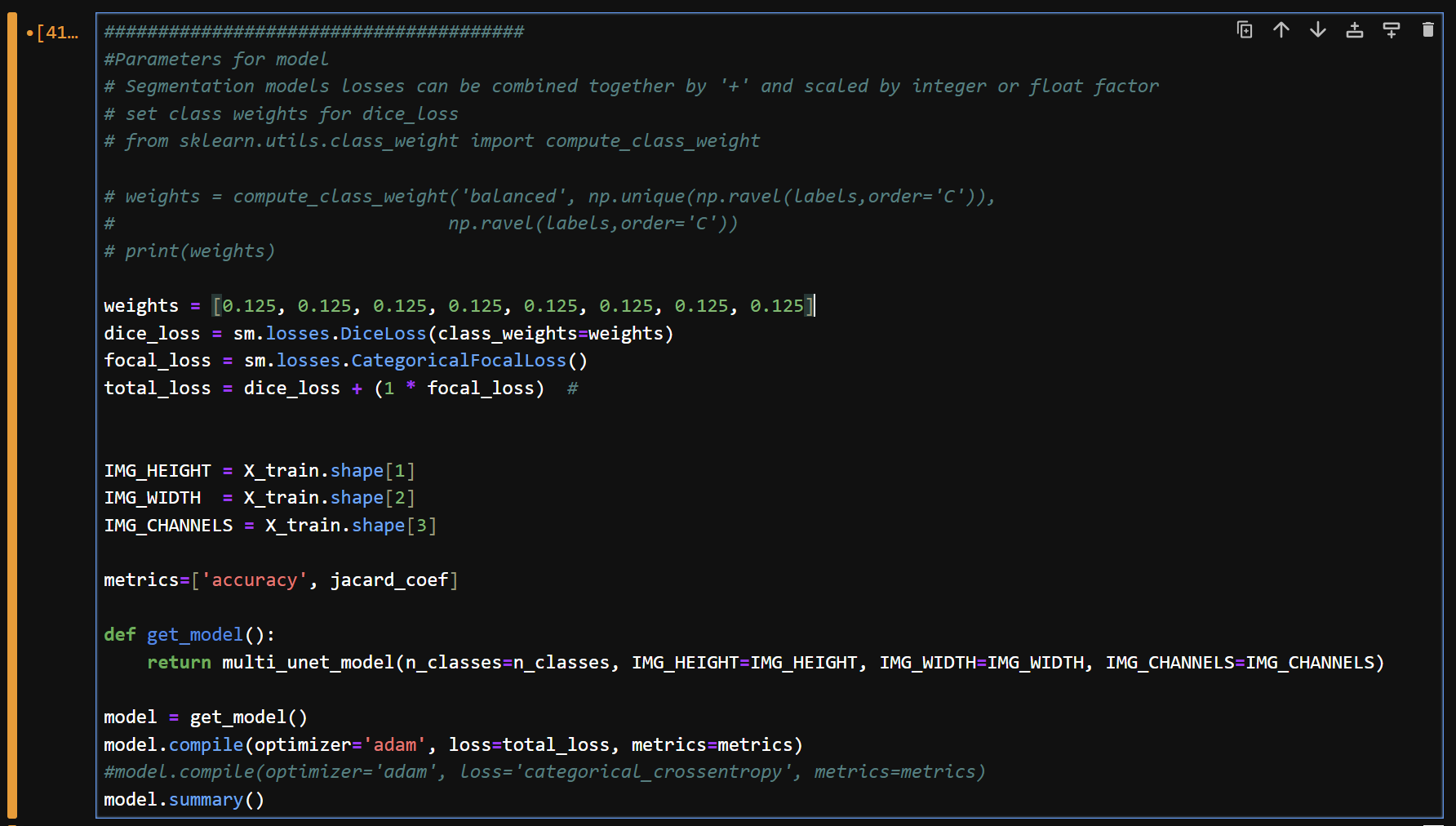
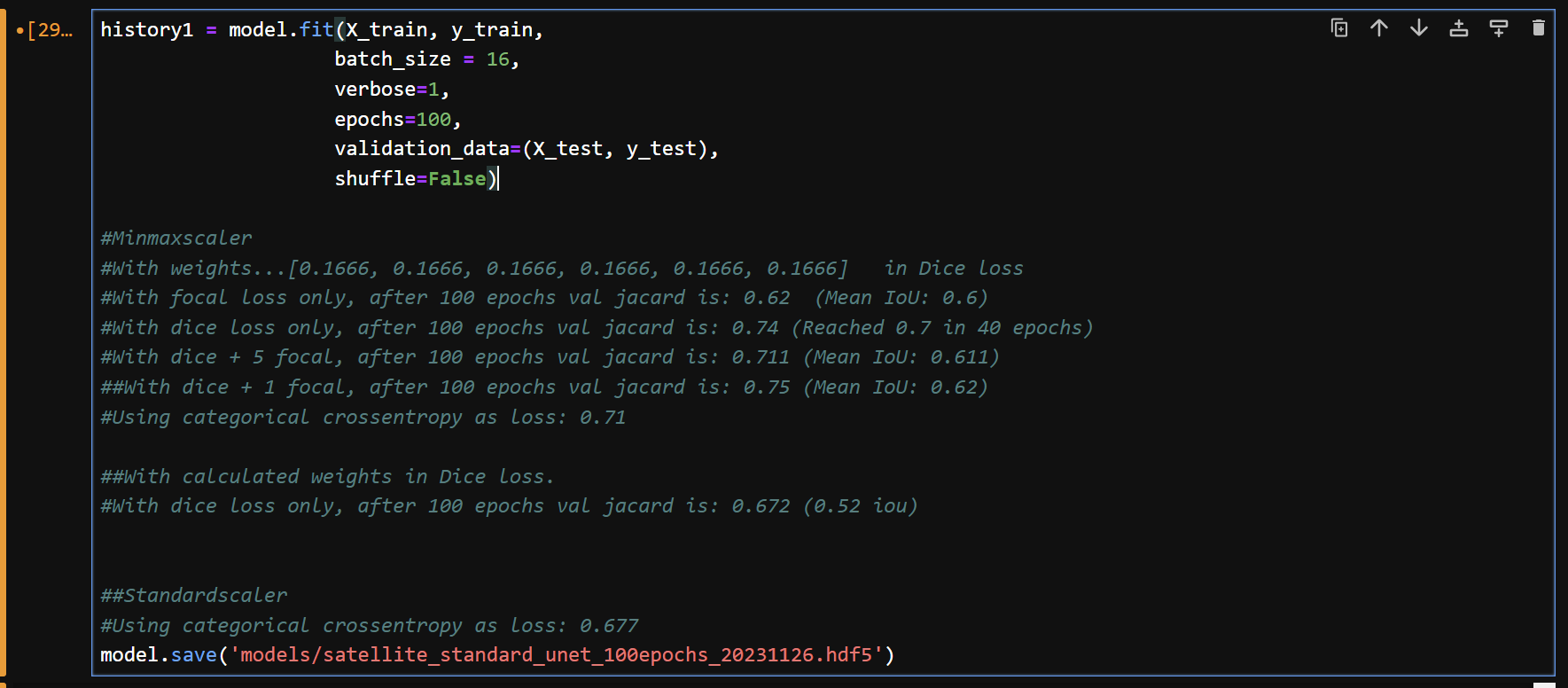
12) 모델을 학습하고 결과를 저장한다.
13) 정확도 변화 확인
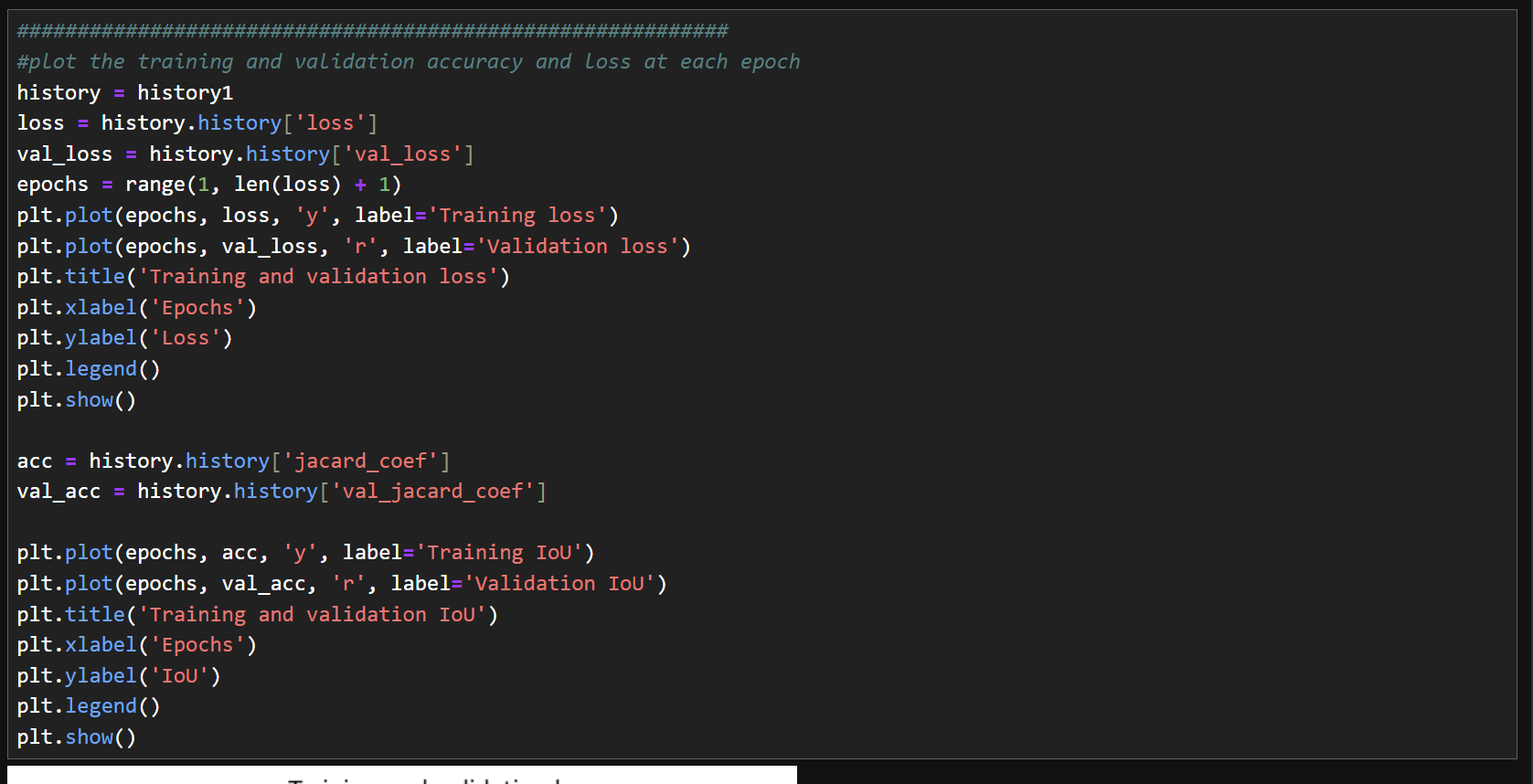
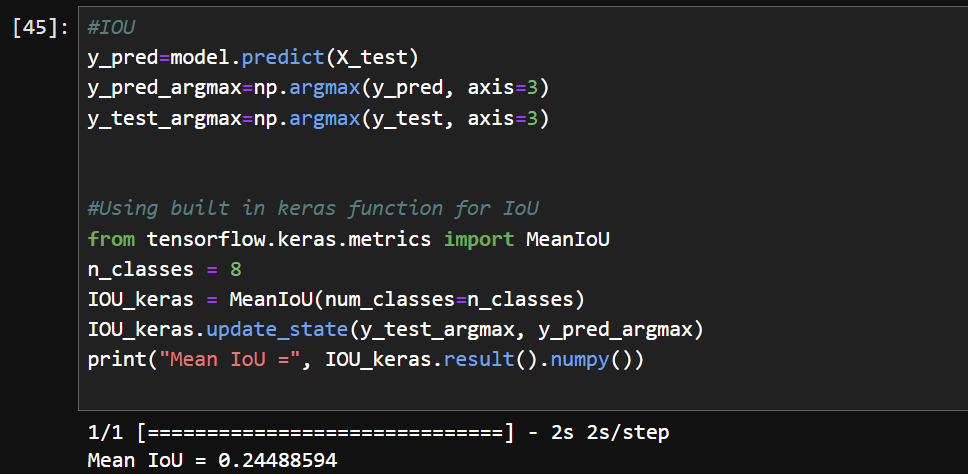
14) IOU 정확도 확인
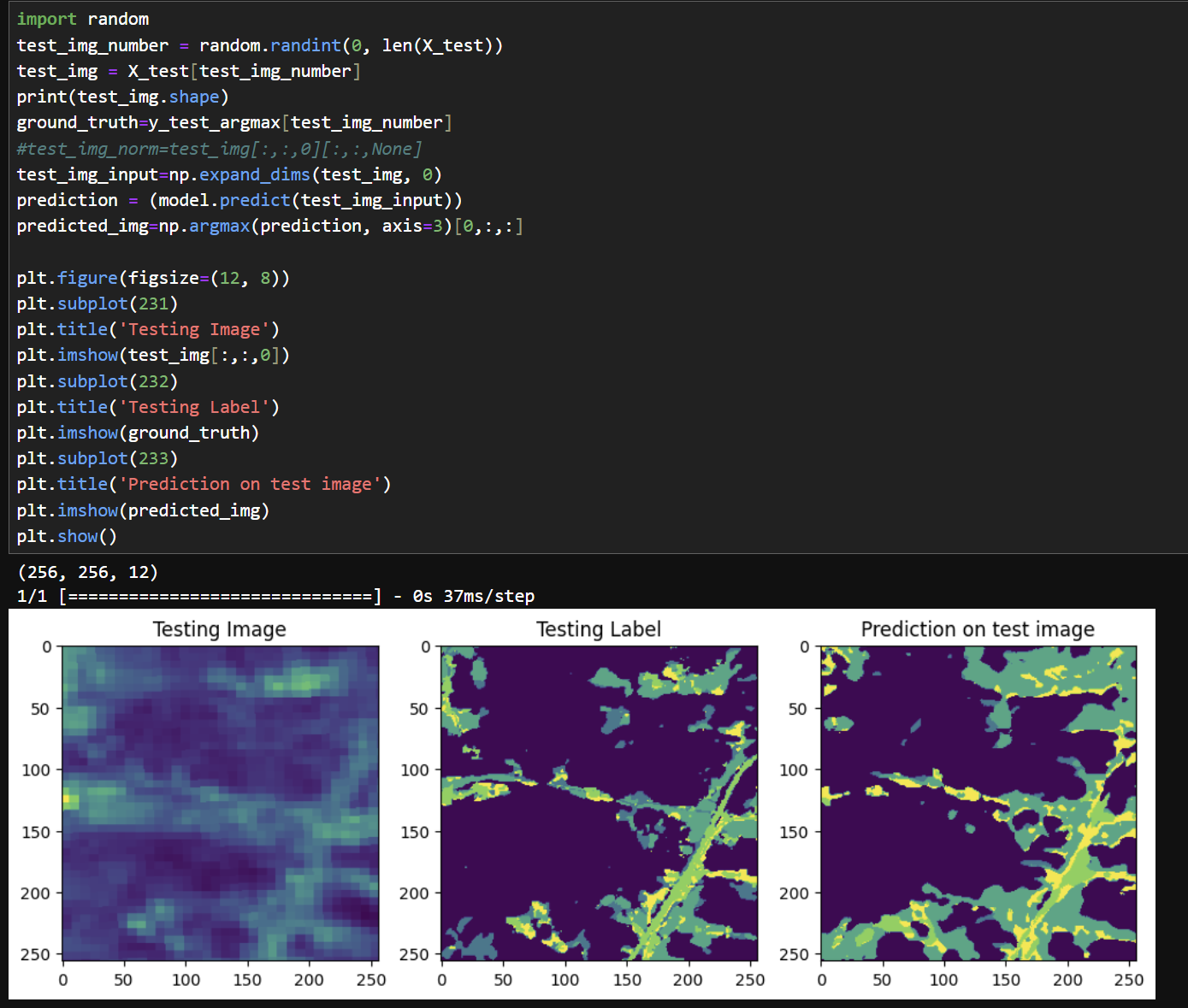
15) 결과 비교
'머신러닝 & 딥러닝' 카테고리의 다른 글
| yolo v8 모델을 이용해서 야생동물 식별 탐지하기 - (3) 심화 예측 (0) | 2023.04.21 |
|---|---|
| yolo v8 모델을 이용해서 야생동물 식별탐지하기 - (2) 기본 예측 (0) | 2023.04.20 |
| yolo v8 모델을 이용해서 야생동물 식별탐지하기 - (1) 설치편 (0) | 2023.04.19 |
| 아나콘다 가상환경 복사하고 붙여넣기, 그리고 삭제하기 (0) | 2023.04.18 |
| 위성영상을 이용한 딥러닝 활용 - 2) 샘플데이터 와 필요패키지 설치 (0) | 2023.04.14 |